What is Retrieval-Augmented Generation (RAG)
May 13, 2025
As businesses increasingly turn to AI for decision-making, content generation, and customer support, one challenge keeps surfacing: trust. Can we rely on language models when they occasionally produce outdated or inaccurate responses?
Retrieval-Augmented Generation (RAG) offers a more reliable alternative. It combines the strengths of retrieval systems with the fluency of generative models, enabling AI to produce coherent answers grounded in real, up-to-date information. This approach brings generative AI closer to meeting enterprise needs.
What Is Retrieval-Augmented Generation?
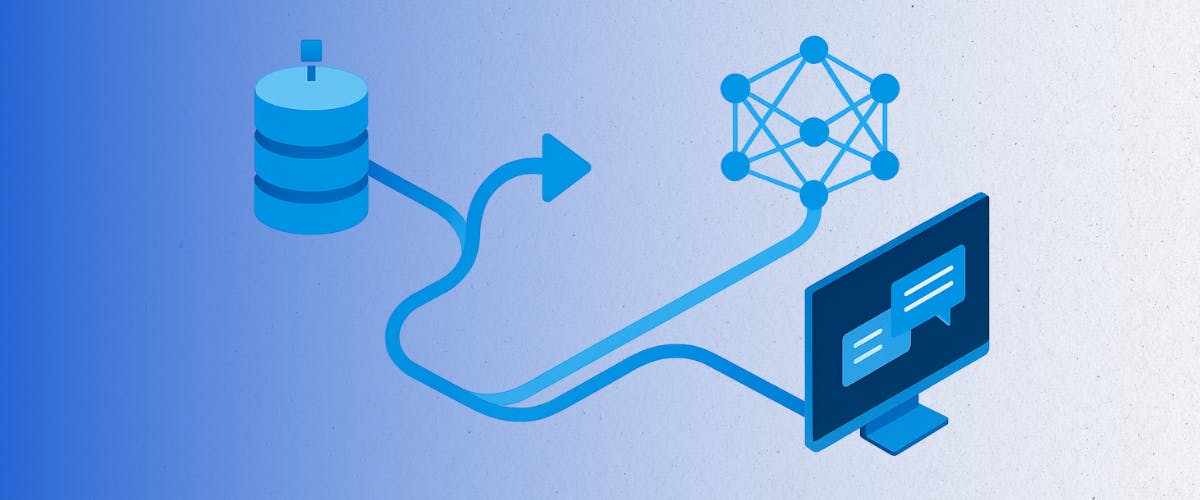
Retrieval-Augmented Generation is an AI framework that enhances traditional large language models by connecting them to external knowledge sources during inference. Unlike standard models that rely solely on pre-trained data, which can become outdated, RAG retrieves relevant information from a live knowledge base. It uses it to inform the generated response.
This process consists of a retriever, which searches for contextually relevant documents or data based on a query, and a generator, which produces a response using both the input and the retrieved material. The result is an answer that reflects current, domain-specific knowledge without retraining the base model.
For instance, when prompted about a recent regulation or an emerging standard, a RAG system can pull directly from updated internal documentation or external sources, providing a more accurate and timely response without retraining the model itself.
Why It Matters
RAG addresses some of the major limitations of standalone generative models:
- Improves relevance by sourcing responses from enterprise-specific or real-time knowledge.
- Enables flexibility, since the retriever can be updated without altering the core model.
- Supports transparency, as systems can cite the retrieved documents used in the response.
This makes RAG especially attractive for high-stakes applications in finance, healthcare, legal services, and enterprise knowledge management.
Real-World Applications
We’re already seeing RAG in action across a range of practical scenarios:
- AI assistants that rely on internal FAQs, policy documents, or technical manuals to support customer service teams.
- Enterprise search tools that allow employees to ask complex questions in natural language and receive grounded responses.
- Legal and medical applications that surface supporting evidence from case law, research studies, or patient records.
- Developer copilots that can explain APIs or workflows by referencing updated technical documentation.
In every one of these examples, the real value comes from combining language fluency with information that’s accurate and contextually relevant.
How It Works
Traditional LLMs generate answers based only on pre-trained data. RAG changes this by adding a retrieval layer that brings in external context before the model responds.
The RAG pipeline typically follows these steps:
1. Prepare the external knowledge base
The external data used in a RAG system resides outside the language model’s pre-trained dataset. This information can come from various sources, including APIs, internal databases, document repositories, or unstructured text. To prepare it for retrieval, embedding models are applied to convert the content into numerical vector representations. These embeddings are stored in a vector database, forming a searchable knowledge base.
2. Retrieve relevant information
When a user submits a query, the system converts the input into a vector and searches for semantically relevant entries in the vector database. The retrieval mechanism calculates similarity scores to identify the most appropriate documents or records. For instance, if a team member asks, “What’s the process for submitting expenses?”, the system could retrieve the company’s reimbursement policy along with that employee’s latest expense report.
3. Augment the LLM prompt
The retrieved data is then combined with the user input to form an augmented prompt. This step applies prompt engineering techniques to ensure the context is presented clearly and effectively to the language model. The model processes the augmented prompt and generates a response that reflects its foundational training and the specific external knowledge provided.
4. Maintain and refresh the knowledge base
Over time, the external knowledge base may need to be updated to ensure accuracy and relevance. This involves refreshing the source documents and re-generating their vector embeddings. Updates can be automated in real time or executed periodically in batch mode. Maintaining current embeddings is essential to ensure the model continues to deliver reliable outputs.
Challenges to Consider
While RAG has clear benefits, it also introduces complexity:
- System design becomes more involved, requiring coordination between retrieval, ranking, and generation components.
- Latency can increase, especially if retrieval and generation aren’t optimized for performance.
- Data quality is critical: poorly structured or irrelevant sources can undermine the system’s reliability.
- Security and governance must be addressed, particularly when retrieving from private or regulated knowledge bases.
Despite these challenges, the modular nature of RAG makes it highly adaptable and scalable for enterprise AI applications.
Why RAG Is Relevant for Custom Software Development
While off-the-shelf language models are powerful, they often lack context, domain depth, and the precision that enterprise use cases demand. That’s where RAG stands out.
By integrating proprietary knowledge into the AI’s reasoning process, RAG allows companies to maintain control over accuracy, compliance, and brand alignment, without retraining the model from scratch.
For software teams building advanced AI solutions, it offers a new level of adaptability. It helps them develop applications that generate answers aligned with business logic, voice, and regulatory expectations, not just generic predictions.
Conclusion
Retrieval-Augmented Generation changes the way we build intelligent systems. It connects language models to real-time data, making AI more accurate and aligned with real business needs.
At Elint, we help companies design tailored AI systems that go beyond hype to deliver real impact. If you’re exploring how RAG or other AI techniques can drive smarter decisions in your organization, let’s talk.
Our website uses cookies. Please note that by continuing to use our website, you are consenting to the use of these cookies. For more information, please refer to our Privacy policy.